
The Abstract Syntax Tree – Kotlin vs. Swift
What if we lived in an imaginary world where you and your colleague could both look at the same source code file seeing Swift code while you look at your preferred language – Kotlin? What if we stored source code in a language-independent way such that every developer in your team could look at the files in their preferred programming language?
🧑💻 How is source code stored
Right now, we store code as text files. It has many advantages: Text files are pretty simple files; One can mess up the encoding but other than that it’s simply a file that contains, well, text. Usually, you’d use an IDE to write source code, but given that it’s just text files, any text editor like VS Code, Notepad++, Nano or even Windows’ built-in notepad can do the job. If you’re adventurous, you could even use Vim (but please google how to exit it before going on that adventure).
The problems
However, if you look at those text files, they are actually fairly inefficient: Things like indentation, whitespace, and even some underscores and braces are only there to make the source code easier to understand for us humans. Indentation has no influence whatsoever on the program’s execution (except if you’re a Python programmer), and yet, we store it in every single source file.
Kotlin vs. Swift
If we compare Swift and Kotlin (or any other programming language for that matter), there are many concepts that are pretty similar: While one language calls functions, func and the other thinks programming is really fun, does adding this 4th letter at the end of the keyword really make a difference to how the program works? It’s understandable that some programmers might prefer reading func rather than fun, but we don’t really need to store that on disk.
A solution?
So, coming back to the idea of converting Kotlin to Swift and vice versa: How could we store source code, such that all of those inefficiencies are gone and that we could easily convert or transpile the code from one language to another?
The idea is already several years old and is actually employed by some tools like Jetbrains’ MPS: What if we compile our code partially into a so-called “abstract syntax tree” (or AST for short) and store that instead?
Precompiling source code before storing it: Let’s store the abstract syntax tree!
🌲 The Abstract Syntax Tree
In order to continue with the discussion, we first need to understand, what the “Abstract Syntax Tree” even is. Every compiler needs to parse the source code and dissect its meaning. To do so, it transforms the source code into a tree structure. It needs this tree to do semantic analysis (which in turn is used to issue compiler warnings and errors). This cannot be done with the source code alone, because source code is actually more ambiguous than you might think.
If we look at things like inferred types in Kotlin, duck typing in Go, operator overloading, or simply custom types (=custom classes), which cannot be defined by a language’s grammar and thus need to be represented by some different structure – a logic tree – or better to say an AST.
Take this statement for example:
result = 40 + 2
The compiler will translate that into a tree that looks something like this:

First of all, the compiler realized that we want to store a value (as a member property in this case) and that the property shall be read-only (as opposed to var result = 40 + 2, which would be mutable). Next to that, it stores the name of the variable and that the type still needs to be inferred (type=null). The + operator that we use in the calculation is a so-called binary operator (shortened to BinaryOp in the tree) because it takes 2 arguments: the number in front of the + and the number after it.
As you can see, all formatting is gone and only our intention is retained: Take the numbers 40 and 2, add them together and store the result in a read-only property called result. And this tree is called the “Abstract syntax tree”.
🤔 Why “Abstract”?
Consider this statement:
val result = (20 + 1) * 2
In that case, the parenthesis indicates that 20 + 1 should be computed first and the result of that multiplied by 2. The abstract syntax tree can omit that parenthesis, because it stores the execution order implicitly, like so:

Again, the compiler saw that we want to store our value as a read-only property. Like the + operator before, also takes 2 arguments and is thus also represented by a BinaryOp node. However, instead of feeding 2 constants into the BinaryOp as we did before, we now feed another, BinaryOp the addition of 20 and 1 into the multiplication. The execution order is thus implicitly represented by the tree as the BinaryOp must be executed first before it can be fed into the multiplication.
The compiler obviously does more things after creating the AST to compile our program, but this is the part we’re interested in at the moment.
🔠 How transpiling would work
So, our goal would be to take Kotlin source code and generate the AST for that. We would then save that AST on disk and whenever we open it, we can choose whether we want to see it as Kotlin or as Swift code.
Let’s take a more complex example:
fun doCalculation(first: Int, second: Int): Int = first + second
The corresponding Kotlin’s AST for this example would look like this:
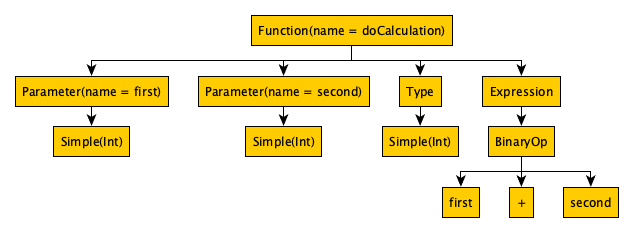
This time, we are using a Function with the name doCalculation and the 2 integer parameters first and second. The AST also contains information about the return type we defined, namely Int. Lastly, the actual calculation is stored in the AST in the Expression node much like our first example.
Using this AST, one can go ahead and construct the corresponding Swift source code:
doCalculation(first: Int, second: Int) -> Int { first + second }
Note that the source file we store at the end contains neither Kotlin nor Swift code, it only contains this tree, from which either can be reconstructed.
🪄 Endless possibilities
Now that we know what an AST is, let’s start dreaming: Formatting is gone in the AST and depending on how the AST is generated, it includes variable names and can also include comments.
So, let’s first start by ending the Tabs-vs-spaces debate: The AST does not include indentation. Every team member could thus have their own preference in his or her editor set and the editor simply renders the AST differently, depending on the indentation setting. The same goes for other formatting options, like if opening curly braces should get their own line or not.
Improved code reviews
Comparing two versions of the abstract syntax tree instead of making a text diff would be so much better. Instead of looking at how the text changed that makes up the program, differences in the AST highlight changes in the program’s logic while ignoring useless changes which don’t even affect how the program works.
How similar are Swift and Kotlin ASTs
In the making of the blog post, we obviously made our hands dirty and looked at both, the AST generated by the Kotlin compiler and the Swift compiler. And it is actually fairly easy to do so: The Swift compiler has a built-in option called -dump-ast, so, by calling swiftc yourSourceFile.swift –dump-ast you can have a direct look at what the AST looks like. For Kotlin, it’s a little more complicated than that, but not much: There’s a library called KAST which can parse any Kotlin file and output the AST for it.
And if you generate the AST for the above example in Kotlin (first figure) and Swift (second figure), you don’t need to look far to spot the first issue:
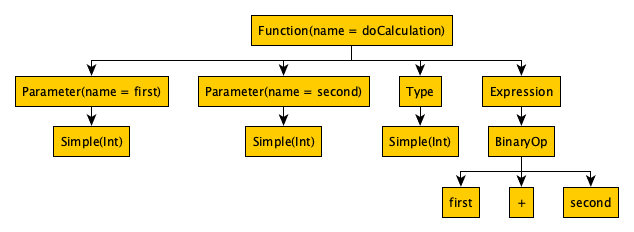

The differences
As you can see, the general structure of the ASTs is similar and they could definitely be translated into each other: While Kotlin calls it a Function and Swift a function declaration both trees contain information about the function name, the parameter list of the function (including the parameter names and types) and the return type of the function. The most significant difference is that Kotlin stores the + operator between the two arguments for it (so-called infix notation) whereas Swift stores the operator first, followed by its arguments (so-called prefix notation or Polish notation). These are easily convertible though. But look at the parameter list of the function in the Swift AST again. Have you noticed the tag apiName ?
If you know Swift, you probably also know that function parameter can have two names: One which is used to refer to the parameter within the function body and another which is used when calling the function, for example, like so:
func doCalculation(firstApiName first: Int, secondApiName second: Int) -> Int { first + second }
doCalculation(firstApiName: 40, secondApiName: 2)
And apiName is the place where this information is stored in the AST.
What should we do with that? We could simply discard that when translating from Swift to Kotlin, but what would we do when translating the other way around? And we haven’t yet started with more complex things, like implementing an interface in an extension, which is possible in Swift but not in Kotlin. Or take Kotlin’s generics features like covariance and contravariance, which would also require weird workarounds in Swift.
The downsides and costs of all of that
If you haven’t realized it yet, the entire approach is completely utopic. Not only would we be limited to the smallest common denominator of language features, but transpiling from one language into another is not as simple as plugging the AST generated by one compiler into the other language’s compiler. Each compiler usually generates an AST which is optimized for that language, and for good reason.
Also, while we can choose which language we want to program in (so-called freedom of language), we lost freedom of tools. While we could write plugins for IDEs like Android Studio, IntelliJ, Xcode or even VSCode, how would we go about merging files in Git or review merge requests? And what about the odd case where you don’t have an IDE available and need to code in a terminal?
And last but not least: What happens with compiler errors? While programmers might avoid committing broken code, one certainly has to save a source code file that contains compiler errors from time to time. And while the AST can represent erroneous code to some extent, it quickly becomes a weird mess and you wouldn’t want your IDE to weirdly squiggle around just because you saved a file that contains a compiler error.
Conclusion
While freedom of language might feel appealing, it’s pretty clear why this approach would never really work. The benefits exist, but they are really small and the downsides far outweigh them. However, working with ASTs, in general, can be useful, e.g. when analyzing, linting, or formatting source code. We thus hope that you liked the excursion to learn a little about how compilers work and enjoyed this fun thought experiment.
If you want to take look at other Kotlin language features these articles might be a good read for you:
Thanks for reading! Also, since this is the first time that we dove into such a theoretical topic on our blog, we would really love to hear your feedback. Have we missed any advantages of ASTs or do you have any other esoteric idea of how to store source code? Hit us up on Twitter!
