
Functional String Parsing in Swift with Ogma: Implementing a Game of Thrones search engine
Engineers deal with a lot of issues on their day to day: complicated flows, race conditions, general error handling. But one issue that always sticks out is that of parsing strings. At QuickBird Studios, we see ourselves always coming back to it.
Personally, I’ve always wanted to build my own programming language and have been very interested in the principles and complexities of many languages. Most notably Swift.
It’s impressive that string Parsers play such an intricate part in the life of all developers. We all seem to have heard and understood some of the principles of how they work. And yet, I get the feeling we never dive deep enough into it. We always stay way up on the surface level.
So I decided to write a String Parser in Swift. In fact, I wrote a Swift Open Source library called “Ogma”, to do the exact same thing. Today, I would like to share some thoughts and experiences, as well as present our suggestion on how to implement a clean Parser architecture.
As an example for this post, we will be extending the capabilities for searching through the Wiki of the popular TV Show: Game of Thrones. We are going to add the feature of adding custom filters to a search query.
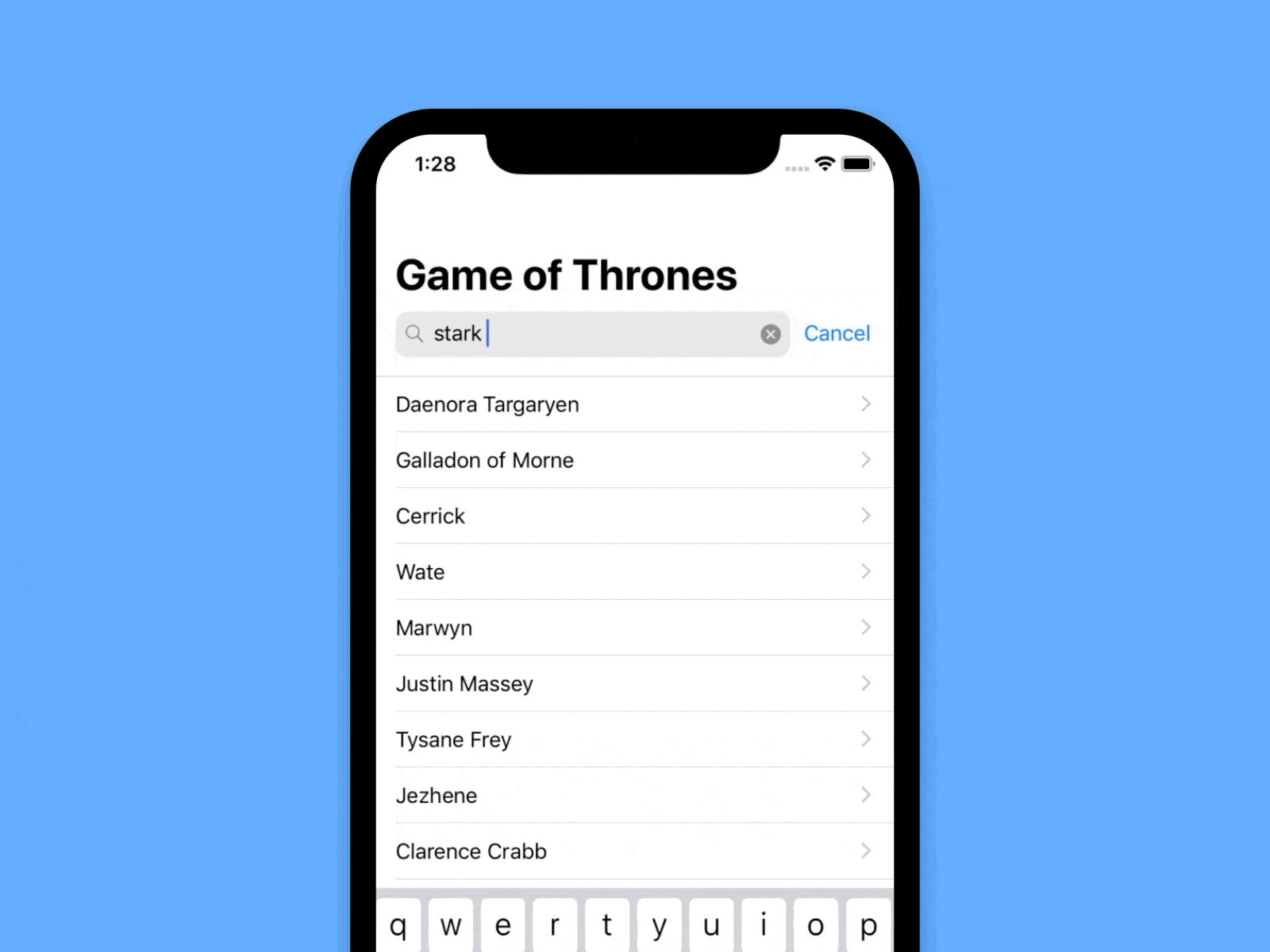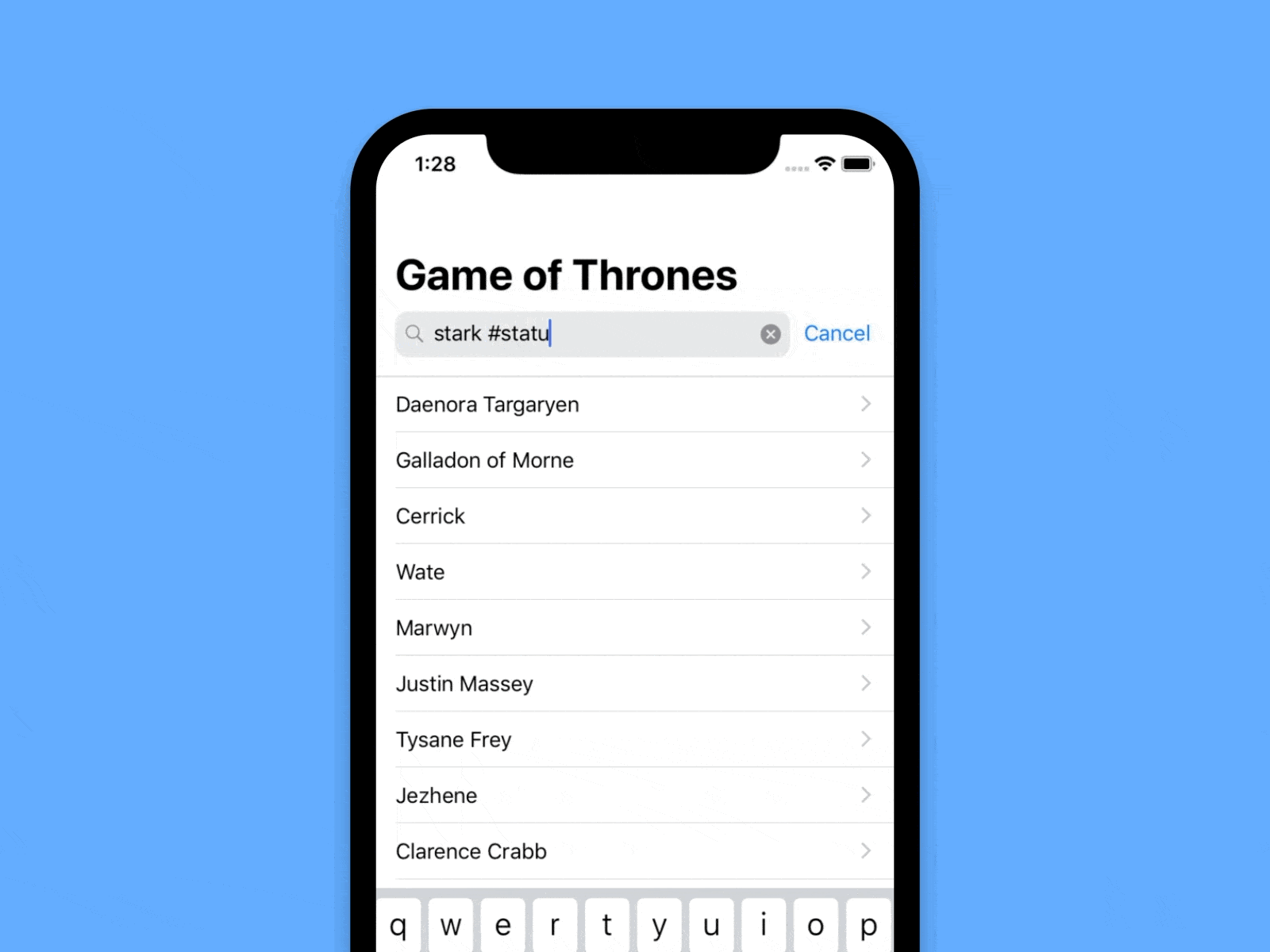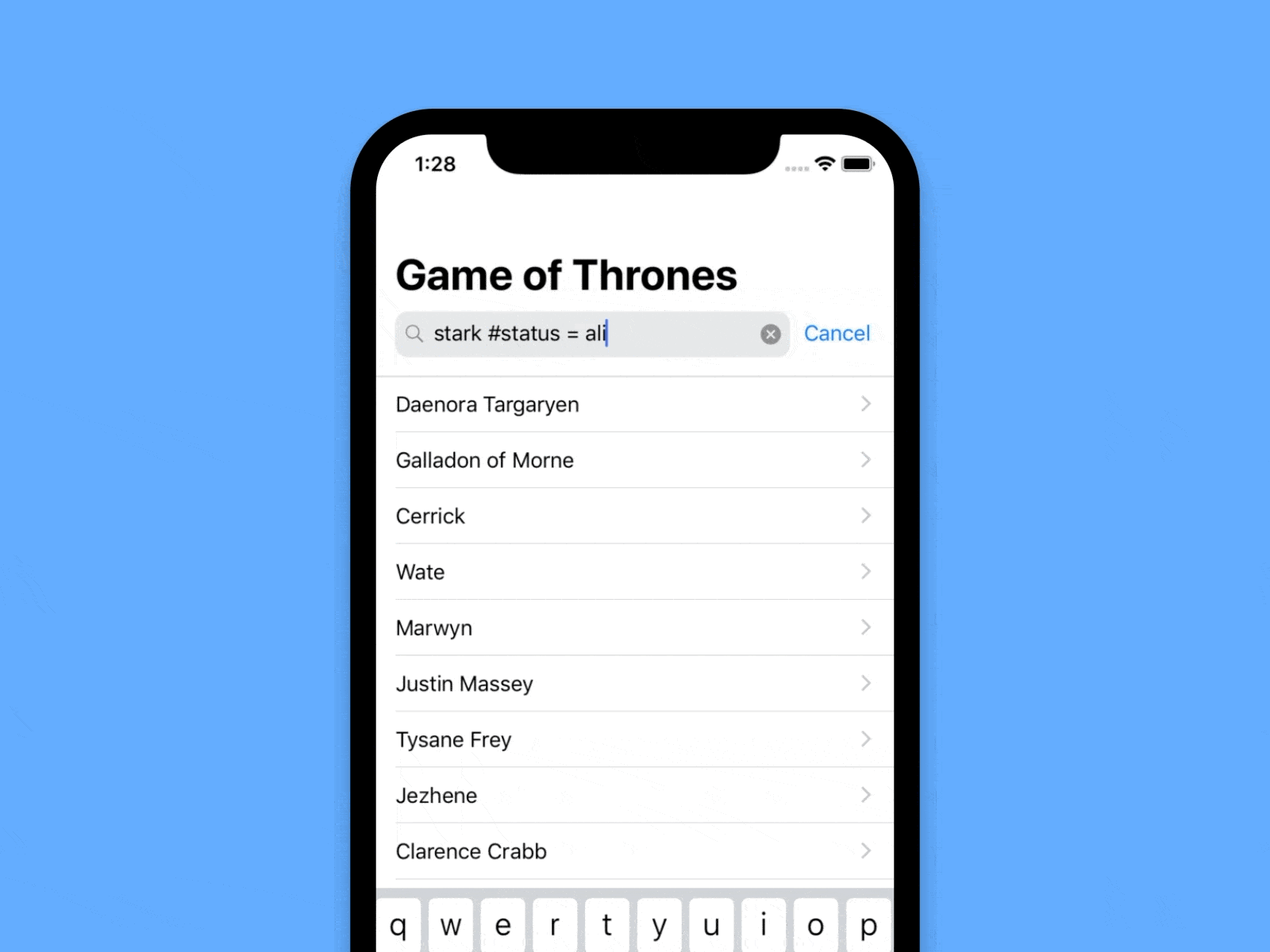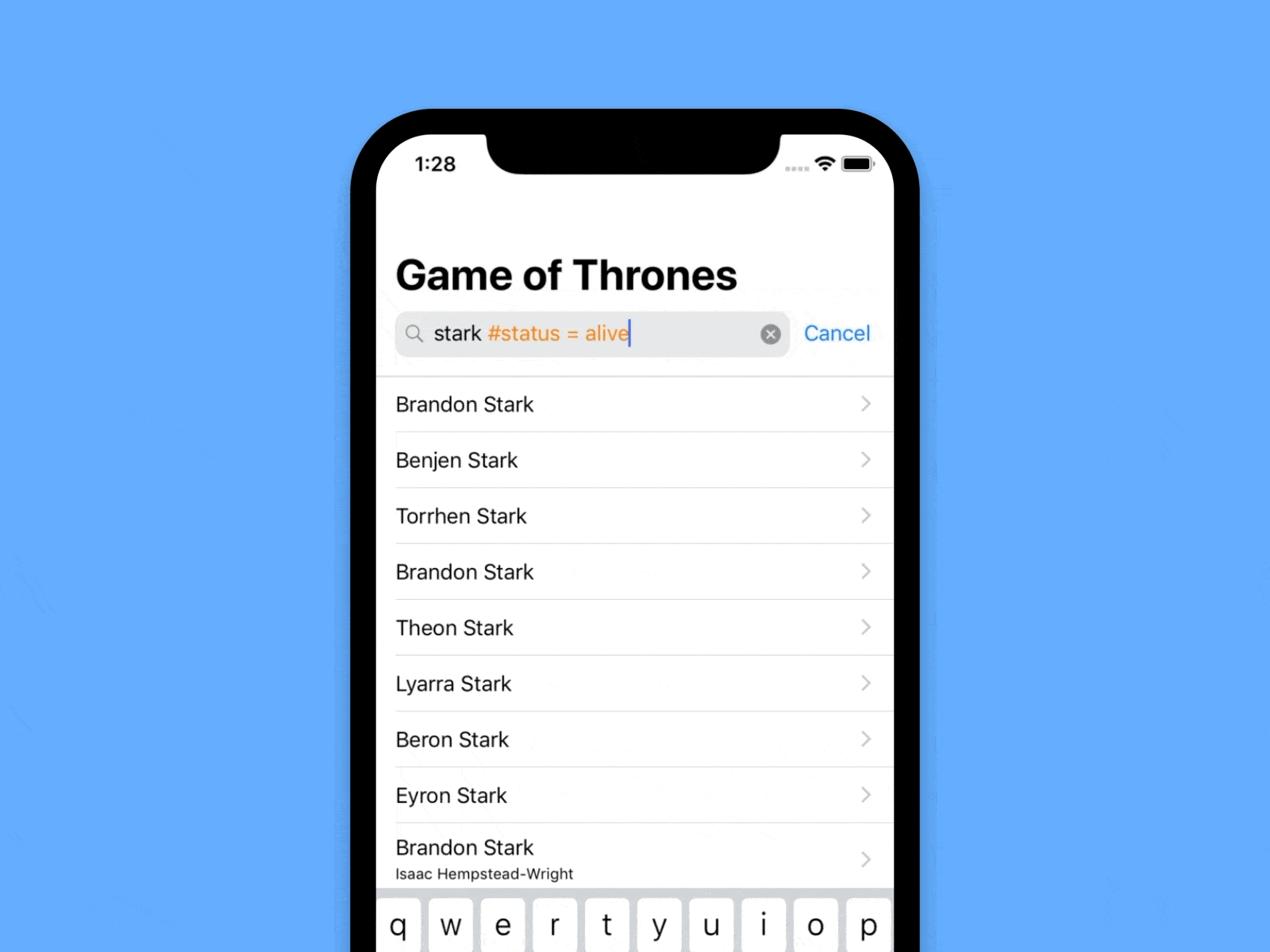
(The results in the video are arbitrarily filtered only by “Stark”, just to make sure we don’t show spoilers here)
But before we get to the code, let’s begin with a very simple question:
Why should I ever write a String Parser
Learning possibilities aside, there are a lot of use cases for having to write a Parser in-house:
- String Parsers are often needed when dealing with Data Formats such as: JSON, yaml and xml.
- These specific ones might be well established already, and have a Parser in almost every language. Yet, there’s always the possibility of new formats making their way mainstream
- Or who knows? Maybe you have to deal with a custom flavor of JSON that breaks all the String Parsers that currently exist in Swift
- Or you decide to write a custom format for your application
- Sometimes you also get user input in your application that you need to evaluate or render.
- Like Markdown or a similar markup language
- Maybe you have to write a custom search query Parser like WolframAlpha’s super cool search function. Like our case with Game of Thrones
- Or maybe you actually want to write your own programming language, well writing a String Parser is a good start for that.
So now let’s dive deep into how a String Parser works in theory. Shall we?!
Theory

So there’s a lot of theory to be dealt with here, and I’m risking sounding like Wikipedia explaining these concepts. People who are already familiar with Context Free Grammars and the standard Parser Architecture can just jump right ahead.
I’ll attempt to make it short and sweet, so this section will be here in case anything from the implementation is unclear ;).
What is a Formal Language?
Ok. Let’s talk about Math. In Math, a language can be seen as a set of all possible words that are considered to be valid.
For example, if you were to start defining the English language you would list every word from A-Z and start by writing the first word in the dictionary: Aardvark (which is a hilarious word to write and the name of the animal you see below). Then, you would continue typing for a very very long time until you listed aaall the possible English words. When it comes to English, there’s no possible way of defining it, without writing down every single possible word there is. That’s why English is not a Formal Language.

The animal called Aardvark, and the first word in the dictionary
A Formal Language would then be defined by a set with clear rules on how we can verify that a word is valid.
For example, we can define all possible email addresses as a Formal Language. We know that contact@quickbirdstudios.com could be a valid email address but contactquickbirdstudios.com is not, because we were expecting an @ separating the “local part” and the domain name.
Now there are a lot of ways of defining Formal Languages, most notably:
- Regular Expressions: if you are not comfortable with regular expressions there are a lot of resources you can check on the topic. We suggest: “An Introduction to Regular Expressions”
- Context Free Grammars
What is a Context Free Grammar?
A Context Free Grammar is a way of describing the rules for a Formal Lanuage. More specifically a Context Free Language (go figure!).
For instance let’s define a simple Grammar for a calculator, where an expression put into the calculator, can either be a number, an addition or a subtraction:
EXPRESSION -> NUMBER | ADDITION | SUBTRACTION
ADDITION -> EXPRESSION + EXPRESSION
SUBTRACTION -> EXPRESSION - EXPRESSION
Note that an Addition contains another expression. That way we can easily chain more and more expressions like these together.
You can also read more on Context Free Grammars on Tutorialspoint.
What even is a Parser?
A Parser is a programm that will take a string as an input, validate if it’s a well formed word in the language and output a model for us to work with.
Alright! Seems simple enough!
Ok? And how are Parsers built?
Very good question! In practice, you want some separation of concerns within your Parser to avoid Technical Debt. One common way is to separate the module into:
- Lexer or Tokenizer: a tool that is responsible for pre-classifying a lot of characters, into what we call Tokens.
- Tokens: an intermediate representation of our characters, with a bit more meaning attached to them, such as numbers, commas, opening and closing parenthesis.
- Parser or Syntactic Analyzer: a component that will turn the pre-computed Tokens into our desired Model. It attempts to derive meaning from a sequence of Tokens as a whole.
- Parse Tree: the structured output of the Syntactic Analysis.
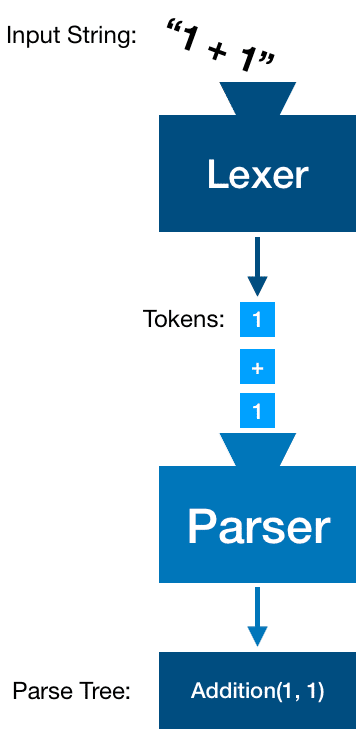
Building a String Parser with Ogma
As noted at the beginning, this post is being published alongside a Swift Open Source Framework called Ogma, designed to build Parsers the way they are suggested here. The main Idea: to program a String Parser in Swift, just like you write down a Context Free Grammar.
So here’s the process, which is very similar to the one portrayed in our theory section:
- Implement the Model: write down the result you are expecting. This will be the Parse Tree at the end.
- Implement the Lexer: Evaluate which Tokens are required by your syntax and map how text should be transformed to these tokens. Don’t worry, most cases are already implemented for you.
- Implement the Parsing: map the transformation from your Tokens to your Model
Now, this might look like a lot of work, but rest assured, that it’s much simpler than you’d expect. So instead of blabbing on about what there is, let us jump straight into an example.
Example: Let’s build a better search for the “Game Of Thrones” Wiki
As the final season of Game Of Thrones started to approach, we at the QuickBird Studios office have been binge-watching all of it. Unfortunately there are sooo many characters in this show. Luckily, there is the Game of Thrones Wiki, a great tool to keep track of what’s going on.
However you might have noticed that their search function could use a little love.
I really wanted to be able to add extra filters, with boolean logic. I wished fore some of the great search query power from Wolfram Alpha, right in this Wiki.
Soooo, let’s just build it – Get a seat, grab some popcorn, and let’s get right into it!
Oh and don’t worry if you haven’t seen Game of Thrones yet: This example doesn’t require any knowledge about the Show and won’t include any spoilers.

Our goal is to have a way to query specific information and use very basic boolean logic. As an example, we’re searching for people…
- …from House Stark (basically, the good guys)
- …who are still alive
- …whose information matches an additional arbitrary query
random query #house = Stark and #status = alive
If we were to parse this example, our ideal output would structured like this (excuse my terrible artistry):
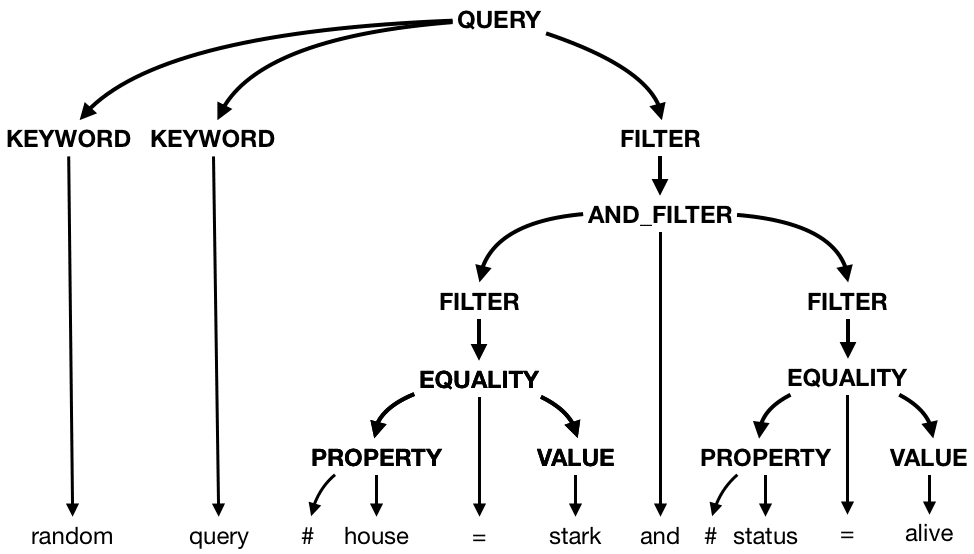
Our Grammar
Let’s begin by defining our Context Free Grammar for this case. We want the user to type a normal search query followed by the more specific filters. So we can say our Grammar roughly looks like this:
- A
Queryis a sequence ofKeywordsfollowed by an optionalFilter - A
Filtercan be:- an
Equalitycheck (is property A equal to B), - a combination of two filters via an
ANDorORgate, - or a
Filterwrapped in parenthesis
- an
Written down on paper, we could define it as follows:
QUERY -> KEYWORD* FILTER?
FILTER -> EQUALITY | AND_FILTER | OR_FILTER | (FILTER)
EQUALITY -> #PROPERTY = VALUE
AND_FILTER -> FILTER and FILTER
OR_FILTER -> FILTER or FILTER
With our grammar written down we can begin with our steps:
1. Writing our Model
As discussed our Model is basically our Parse Tree. We should be able to read what the user wanted from this Model alone.
So we begin with the Query, roughly as explained above:
Now we can model the individual parts such as the Keywords:
And the structure of a Filter:
Here in the Filter we mention an Equality, which models a Filter that checks for equality between a property and a value, like #house = Stark in our original example. We model it using structs:
In this scenario we are also using BinaryOperation, which is a struct already included in Ogma, that will deal with the parsing operations as well as operator precedence for us. The generic parameter for BinaryOperation just means that on each side of the operation will be a Filter.
Now, we define the operations. For this we also have to implement MemberOfBinaryOperation, to signal that it can be used for Binary Operations:
We are now providing the operator precedence via the position in the enum. This means that and always goes before or. Really handy, isn’t it?
2. Implementing our Lexer
To write our Lexer we first have to decide what our tokens are. By the looks of our Grammar, we have to support:
- Single Words
- #
- =
- parenthesis
We would also like to support String Literals in case the value you’re comparing is more than one word.
For example: #title = "King of the North"
So we can write our Token enum:
A Lexer can be built using what we call TokenGenerators. A TokenGenerator will attempt to match parts of the String to a Token. We will need:
WhiteSpaceTokenGenerator: that matches any white space. Usefull for ignoring spacing.RegexTokenGenerator: that matches a Regular Expression to a Token.StringLiteralTokenGenerator: that matches a String inside quotation marks.
This way our Lexer can written as:
3. Parsing
Now, at the final stage, we just connect the dots. We have to explain how we expect these objects to be composed and how to map the result from them. We do this by letting our model implement Parsable, which specifies a Parser for each type.
Let’s start by writing two helpers for Token. To make getting words and string literals easier:
Now, with that out of the way, we can model how a Keyword looks like. Let’s remember what it looked like in our tree:

Since it’s just a word we can model it as the Parser that attempts to consume the word property from a Token:
The function consuming takes a KeyPath of Token to try to use that as the output. We can do almost the exact same thing with a Property. Only this time we expect a # right before it:

By using the && operator we create a chain. It is expecting a Token.hash followed by a word.
Next, for our Value it can either be a bare word or a String literal:

This time we’re using the || operator to signal that we want to use the first result that succeeds. If it’s not a bare word, then try a string literal.
Now our Equality struct just has to be a property, followed by a =, followed by a value:
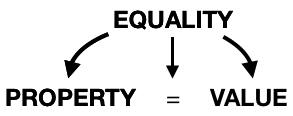
Notice that we’re just chaining the types that we are expecting to be there. And simply mapping the result to our struct.
We are almost done with our Filter:
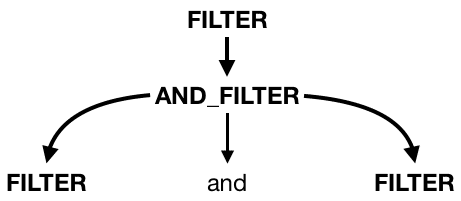
We’re again using the || operator to combine multiple possibilities. But this time we’re also using Filter to define Filter again in:
This just means that it’s also allowed to have a Filter again, but wrapped in parenthesis like so: (FILTER)
Finally the only type where we have to implement Parsable is our Query:
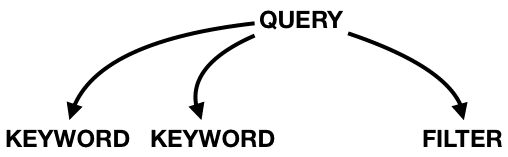
This time using the * postfix to signal that it can happen any number of times in a sequence and by using Filter? to signal that it’s optional and it should not fail it it isn’t there.
Let’s test it out to see what we get!
And get as an output:
{
keywords = 2 values {
[0] = "random"
[1] = "query"
}
filter = operation {
lhs = equality = {
property = "house"
value = "Stark"
}
rhs = equality = {
property = "status"
value = "alive"
}
operator = and
}
}
So that’s it! We built a Parser, for our own custom search queries!!!
And only using very small pure functions 🤟🏼💪🏼😎.
You can see the full implementation here.
Conclusion of writing a String Parser in Swift
Look! Writing reliable software is hard. And writing software that understands text can be one of the more complicated tasks. Most of the time, we developers use Parsers that were built by someone else with more experience. But in our opinion, Ogma is a good way to build a custom parser crafted to match your needs if you:
- don’t have a pre-made solution available
- or want to support extra cases that aren’t standard yet (like parsing specific search queries)
- or don’t want to rely on someone else’s implementation, that might also become outdated over time
- or prefer the flexibility that comes with using your own parser
It’s mainly a good start if you want to play connect the dots, and have a working product quickly, that’s easy to extend and maintain. Which is freaking awesome!
There are a lot more examples on what this Library can do. For instance to see our own short implementation of a fully working JSON Parser go here: Link to Code.
If you’re interested more in the Topic, please do check out the library on GitHub! Or check out any of the following resources on the topic:
- John Sundell’s Article on Parsing in Swift
- Harlan Haskins’ Article on Compiler Construction in Swift
- William W World’s Article on Compiler Construction
- Phil Eaton’s Article on Writing a JSON Parser
- The Class on Compiler Construction from the Technical University of Munich
We’ll be here watching Season 8 unfold. Happy Hacking ❤️
